

Автор: Талабуев Я.
Как показывают исследования, любой бизнес находится в зоне риска. Одни только программы-вымогатели приносят огромный ущерб: как в виде затрат на выкуп, которые в корпоративном сегменте достигают десятков миллионов долларов, так и в виде последствий незапланированных простоев. Кроме того, возможны стихийные бедствия, серьезные аппаратные и программные сбои — все, что может временно, частично или полностью, парализовать работу компании. Чтобы быстро вернуться в штатный режим, требуется серьезная подготовка — разработка и реализации стратегии аварийного восстановления (Disaster Recovery).
- Что включает аварийное восстановление
- Самое важное о стратегии аварийного восстановления
- Как реализовать стратегию аварийного восстановления за 5 шагов
- Какое решение выбрать для аварийного восстановления?
Проблема восстановления работоспособности бизнеса после сбоев в работе IT-инфраструктуры все больше интересует компании всех размеров. В связи с этим, по подсчетам IDC, в прошлом году они суммарно потратили только на кибербезопасность и решения в сфере аварийного восстановления не менее $219 млрд, то есть на 12% больше, чем годом ранее. Эти затраты оправданы, ведь именно от того, как бизнес реагирует на нештатные ситуации, зависит его устойчивость и способность удержаться на рынке.
Еще немного статистики:
- Самые распространенные причины простоев — проблемы с сетью, ПО и отключения электроэнергии (источник: Uptime Institute).
- В результате атаки программ-вымогателей компания простаивает в среднем 16 дней (источник: Coveware).
- 82% простоев, спровоцированных кибератаками, вызваны человеческим фактором (источник: Verizone).
- По итогам 2023 года атаки программ-вымогателей затронули 72,7% компаний по всему миру (источник: Statista).
- В 2024 году 79% компаний планируют увеличить свои бюджеты на кибербезопасность (источник: TechTarget).
Что включает аварийное восстановление
Стратегия аварийного восстановления объединяет план аварийного восстановления (DRP, Disaster Recovery Plan), план обеспечения непрерывности бизнеса (BCP) и план реагирования на инциденты. Они покрывают собой все незапланированные инциденты, которые потенциально могут привести к простою: от перебоев с электроснабжением и стихийных бедствий до кибератак.
Многие организации ограничиваются только DRP, в котором подробно описывается план действий в случае возникновения различных инцидентов. Разрабатывают этот план либо внутри компании, либо в соавторстве с поставщиком решений по аварийному восстановлению.
Талабуев Я.,Product Manager в Colobridge GmbH:
«К нам обращаются всего как к поставщику экспертизы и ожидает, что мы не только предоставим вычислительные мощности для аварийного восстановления после сбоя, но и поможем с выбором оптимальных параметров восстановления, а также разработкой плана действий в критичной ситуации. Почему это так важно? Одна и та же проблема по-разному влияет на разный бизнес. Однако на самом деле все компании преследуют одинаковые цели. Они стремятся обеспечить непрерывность бизнеса и быстро вернуться к нормальной работе, избежав длительных простоев. Точно также они заинтересованы сократить материальный ущерб от простоев и в целом уменьшить их количество и частоту. Особенно высокие требования выдвигают компании, которые работают в регулируемых сферах: например, государственном или финансовом секторе, но также те, где даже несколько минут простоя исчисляются крупными суммами».
Самое важное о стратегии аварийного восстановления
Качественно проработанная стратегия аварийного восстановления должна учитывать как можно больше вероятных угроз, описывать последствия их наступления и предлагать решения в каждом конкретном случае. При создании подробных инструкций для реагирования в чрезвычайных ситуациях обычно оперируют несколькими понятиями, описанными ниже.
- RTO (Recovery time objective, «целевое время восстановления») — время, в течение которого IT-системы будут оставаться недоступными после инцидента.
- RPO (Recovery point objective, «целевая точка восстановления») — период времени, за который данные могут быть потеряны. По факту это данные, которые компания может позволить себе потерять без серьезного ущерба.
- DRaaS (Disaster Recovery as a Service, «аварийное восстановление как сервис») — услуга аварийного восстановления IT-инфраструктуры на мощностях поставщика услуги, чаще всего облачного провайдера. Именно он создает, управляет и поддерживает инфраструктуру для восстановления работы сервисов клиентов, а также предоставляет необходимые программные инструменты.
По данным Fortune к концу 2024 года рынок DRaaS составит $12,8 млрд, а к 2032 году достигнет $64,4 млрд со среднегодовым темпом роста 22,4%. Росту рынка в числе прочих факторов способствует массовое внедрение систем генеративного ИИ.


Как реализовать стратегию аварийного восстановления за 5 шагов
Эти шаги будут универсальными для любого бизнеса независимо размеров и сферы деятельности.
Оценка последствий угроз
Необходимо понять, как возможный простой IT-инфраструктуры повлияет на конкретный бизнес. Для этого используют BIA (Business Impact Analysis) — изучение последствий, к которым приведут те или иные риски (кибератаки, стихийные бедствия, вызванные человеческим фактором и другие ошибки) и того, как они повлияют на ключевые бизнес-процессы или компанию в целом. Она должна понимать, как простой в работе может трансформироваться в репутационные и материальные потери. Последние включают как убытки в моменте (недополученная прибыль), так и штрафы, которые накладывают регуляторы рынка в некоторых сферах.
Оценка рисков
Выше мы говорили о последствиях наступления неблагоприятных инцидентов, но какая вероятность их наступления? Это можно выяснить в процессе детального анализа рисков RA (Risk analysis), в ходе которого отдельно рассматривается каждая угроза и вероятность ее наступления.

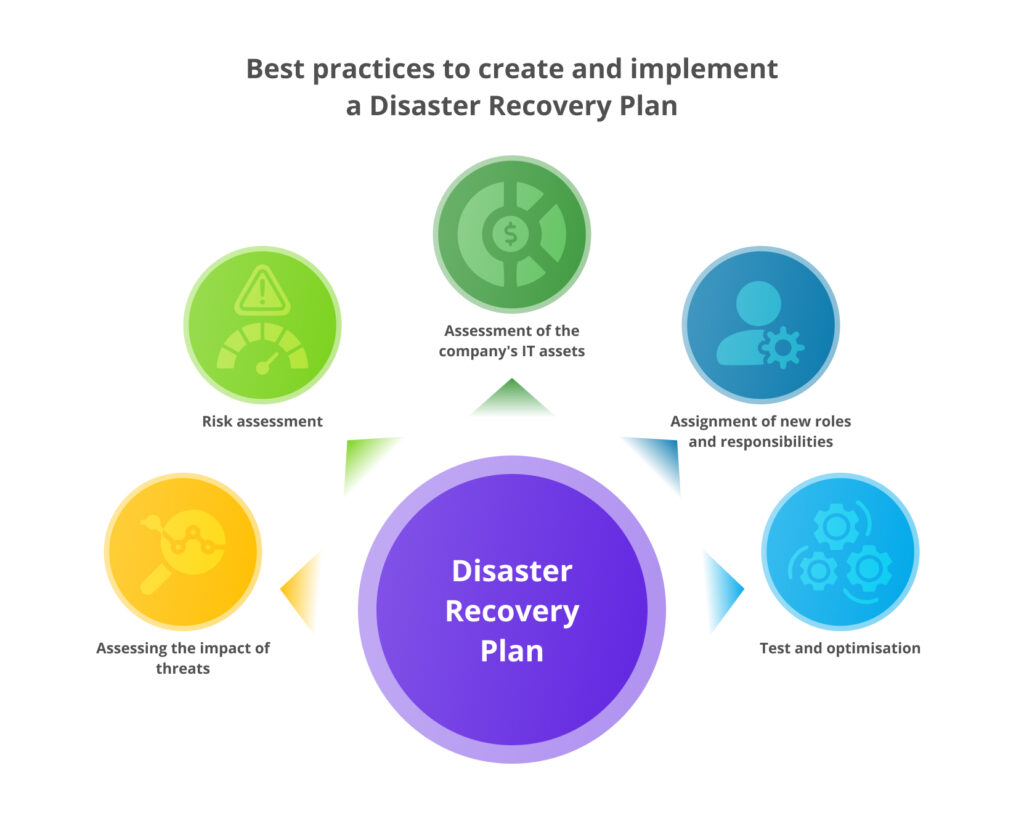
Оценка IT-активов компании
Эффективное аварийное восстановление возможно только тогда, когда компания понимает ценность всех своих IT-активов. К ним относят вычислительное и сетевое оборудование, программное обеспечение и все то, что играет важную роль в обеспечении непрерывности бизнеса. Следует выделить наиболее критичные, важные и второстепенные компоненты. Например, критичными называют те, без которых невозможно выполнение текущих бизнес-операций, а важными — те, которыми компания пользуется по крайней мере один раз в день.
Назначение новых ролей и обязанностей
Кто будет отвечать за реализацию плана аварийного восстановления? Вам предстоит однозначно ответить на этот вопрос и четко прописать обязанности этого сотрудника. От него во многом будет зависеть скорость и эффективность послеаварийного восстановления. В крупной компании ответственных лиц может быть несколько. Например, один сотрудник оперативно оповещает о наступлении инцидента топ-менеджеров компании и других заинтересованных лиц. Менеджер DRP контролирует, чтобы все ответственные за аварийное восстановление четко следовали инструкциям и действовали согласованно. А менеджер активов обеспечивает безопасность критично важных активов и отчитывается об их состоянии.
Тест и оптимизация
Разработка стратегии аварийного восстановления — не разовое мероприятие. Даже после того, как вы убедитесь в ее жизнеспособности, необходимо будет постоянно дорабатывать и улучшать отдельные процессы. И на каждом этапе потребуется тестирование в условиях, приближенных к реальным. Это поможет выявить и устранить ошибки до наступления реального инцидента.
Какое решение выбрать для аварийного восстановления?
Компания Colobridge поможет вам реализовать стратегию аварийного восстановления и убедиться в ее эффективности. Отказоустойчивая платформа на базе двух независимых дата-центров в Германии, ПО ведущего мирового вендора в сфере решений для резервного копирования и экспертиза наших специалистов позволят получить максимум от услуги DRaaS в рамках вашего бюджета. Напишите нам, чтобы узнать больше о данном продукте: преимуществах перед обычным резервным копированием (эту услугу также можно заказать у нас), основных возможностях и ценообразовании.


