

Автор: Волнянский А.
Невозможно знать все, но важно знать, где находить информацию по необходимости — таким принципом руководствуются большие языковые модели с RAG. Рассказываем, как работает этот подход и как он оказывает влияние на качество и полноту ответов.
- Что такое RAG в ИИ
- Преимущества RAG
- Как работает генерация, дополненная поиском
- Где и как использовать RAG
- Проблемы и вызовы генерации, дополненной поиском
- Будущее RAG
- Самое главное о дополненном поиске RAG
Что такое RAG в ИИ
RAG (Retrieval-Augmented Generation) — это генерация с дополненной выборкой или же процесс поиска ответа на вопрос пользователя к большим языковым моделям (LLM), который сопровождается подключением к дополнительным источникам. Это могут быть внешние базы данных, внутренние документы компании, интернет-статьи, научные и другие источники данных. То есть модель RAG позволяет большой языковой модели получать доступ к информации, которая изначально не входила в ее учебную базу. Появление RAG стало важным этапом развития больших языковых моделей, так как позволяет заполнить пробел в их работе, генерируя максимально точные ответы с учетом контекста.
Например, вы хотите создать чат-бота с ИИ для магазина цифровой электроники, чтобы автоматизировать работу службы поддержки. С помощью LLM вы будете генерировать ответы только на общие вопросы, касающиеся особенностей конкретных товаров. RAG делает ответы не универсальными, а максимально релевантными: так пользователи смогут узнать точное время работы офлайн-магазинов, сроки доставки товаров, условия гарантии и другую информацию, которая касается конкретно вашего бизнеса.

Впервые термин RAG использовал Патрик Льюис в 2020 году в своей статье для Meta’s AI Research. Тогда он описал, как использовать генерацию дополненной реальности для задач обработки естественного языка (NLP), которые требуют значительных знаний.
RAG превращает LLM из универсального средства поиска ответов в более точное. Поэтому RAG используют там, где пользователям необходимы авторитетные, глубокие ответы, основанные на конкретных источниках. Для оценки релевантности ответов, полученных с помощью RAG, используют как автоматические метрики (например, BLEU, ROUGE, BERTScore), так и помощь реальных экспертов, которые проверяют часть ответов вручную.
Наряду с RAG для повышения точности ответов LLM используется тонкая настройка, которая также адаптирует большую языковую модель к конкретным сценариям использования. Хотя оба метода решают одну и ту же проблему, между ними большая разница.
RAG против тонкой настройки в повышении точности ответов LLM:
| Критерий | RAG (Retrieval-Augmented Generation) | Тонкая настройка LLM (Fine-tuning) |
|---|---|---|
| Суть | Подключение LLM к внешним источникам данных (базы, документы и т.п.) | Переобучение модели на специализированных помеченных данных |
| Актуализация данных | Позволяет использовать всегда актуальные данные в режиме реального времени | Требуется периодическая переобучение модели для обновления знаний |
| Гибкость | Высокая, легко адаптируется под различные источники и типы данных | Ограничена набором данных, на которых была проведена тонкая настройка |
| Скорость внедрения | Быстрее, так как не требует переобучения модели | Дольше, требует время на сбор и подготовку данных и тренировку модели |
| Особенности использования | Подходит, если данные часто меняются или Большой объем разнообразной информации | Эффективна для фиксированных, хорошо структурированных доменных данных |
| Риск «галлюцинаций» | Меньше, так как ответы основаны на реальных данных | Выше, если модель не дообучена или данные устарели |
| Пример сценариев | Корпоративные базы знаний, поддержка клиентов, поиск по документам | Чат-боты с глубоким доменным знанием, модели для аналитики данных и классификации |
Преимущества RAG
RAG позволяет избежать крупных затрат на при адаптации моделей ИИ для конкретной сферы использования. Качество ответов при этом повышается, но это не единственное преимущество генерации, дополненной поиском. Другие возможности этого подхода включают:
- Сокращение риска галлюцинаций. Иногда ИИ-модели обнаруживают взаимосвязи, которых на самом деле не существует, или возвращают пользователю выдуманную информацию. С RAG количество таких случаев сокращается, так как ответы подкрепляются более авторитетными и актуальными данными.
- Рост доверия со стороны пользователей. Повышение точности ответов на фоне снижения частоты галлюцинаций позволяет завоевать доверие пользователей. Они также могут проверить точность ответа по источникам, которые предоставляет ИИ-модель.
- Более широкие возможности применения. Использование RAG означает, что модель может обрабатывать больше сложных запросов из множества достоверных и авторитетных источников.
- Повышенная безопасность данных. Доступ к внешним источникам, которые использует модель при генерации ответов, дополненных поиском, может быть отозван в любой момент.
- Экономический эффект. Компании, которые подключают RAG, избегают затрат на переобучение моделей, более рационально используют человеческие ресурсы и сокращают количество ошибок в ответах LLM — все вместе это дает финансовый результат.
Как работает генерация, дополненная поиском
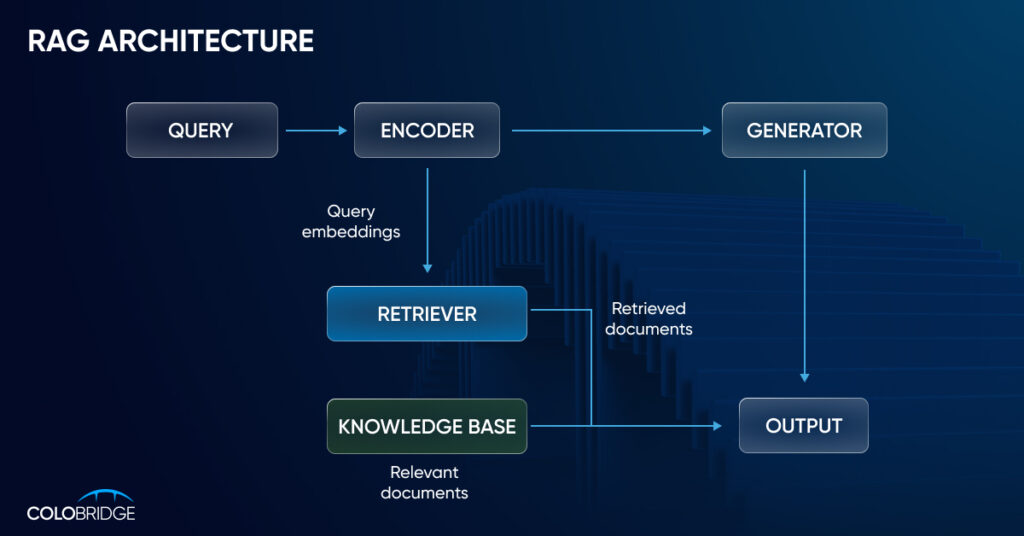
Генерация с дополненной выборкой начинается с создания базы внешних данных. К ним большая языковая модель будет обращаться для того, чтобы возвращать пользователю более точные, полные и аргументированные ответы. Типичные источники — базы данных, API, репозитории документов разных типов и форматов.
На следующем этапе необходимо обеспечить релевантный поиск. Такой, при котором ИИ чат-бот будет выбирать дополнительные источники, необходимые для генерации правильного ответа. Например, пользователь обращается к корпоративной базе данных с вопросом о том, как он может повысить свою квалификацию с компенсацией обучения от компании. В таком случае чат-боту будет необходимо подключиться к репозиторию внутренних документов, найти там подтверждение возможности такого обучения, а затем — к соответствующим внутренним распоряжениям. И, наконец, RAG обогащает свои данные с учетом контекста запроса пользователя, запрашивая дополнительные подсказки.
Визуально процесс поиска решения с помощью ИИ RAG представлен на изображении ниже:
Где и как использовать RAG
RAG значительно расширяет возможности использования больших языковых моделей в бизнесе. Вот несколько примеров, которые это демонстрируют.
Оптимизация работы маркетингового отдела
RAG помогает специалистам по маркетингу генерировать точный, соответствующий tone of voice контент, делая это быстрее и с меньшим количеством ошибок. Используя сведения о микросегментах клиентской аудитории, компания может создавать практически неограниченное количество гиперперсонализированных email, рекламных объявлений, push-сообщений на основе актуальных маркетинговых материалов, бренд-бука, информации о продукте, часто задаваемых вопросов клиентов, запросов в поддержку, исторических и других сведений. Кроме этого, системы на базе RAG позволяют извлекать пользу из актуальных обзоров рынка, аналитики, трендов, чтобы адаптировать маркетинговую стратегию под быстро меняющийся рынок и лучше соответствовать ожиданиям целевой аудитории.
Если вы хотите регулярно создавать правильные и своевременные сообщения для каждого микросегмента аудитории, воспользуйтесь нашей платформой для гиперперсонализации beinf.ai. Это поможет улучшить опыт клиентов, сделать их более лояльными вашему бренду и в конечном итоге повысить доходы компании.
Клиентская поддержка
Благодаря RAG клиенты смогут получать более точные и развернутые ответы на свои вопросы о товарах и услугах компании. Например, точные спецификации продуктов и рекомендации по устранению неполадок из официальной документации к ним. Это улучшает клиентский опыт, повышает доверие к бренду и лояльность, а в долгосрочной перспективе положительно влияет на доход компании.
Работа с корпоративной базой знаний
В больших компаниях сотрудникам приходится работать с большим количеством внутренних документов и руководств. Благодаря RAG сотрудники могут узнавать об актуальных изменениях в правилах и политиках компании, действующих социальных гарантиях или о том, на каких условиях можно перейти на гибридный формат работы.
Борьба с мошенничеством
Системы на базе RAG автоматизируют и ускоряют расследование случаев мошенничества, а также упрощают обмен оперативной информацией между подразделениями компании. Это позволяет быстрее идентифицировать риски и принимать соответствующие решения.
Более эффективная работа с данными
Благодаря RAG можно оптимизировать процедуру поиска и согласования данных, которые хранятся в разных подразделениях и системах. Для крупной компании это может быть проблемой: данные часто не синхронизированы, отсутствует единая система поиска, есть дублирующая или, наоборот, конфликтующая между собой информация.

Проблемы и вызовы генерации, дополненной поиском
Свою изначальную задачу RAG выполняет: эффективность работы с LLM действительно растет, галлюцинации сокращаются, а ответы выходят за рамки тренировочных данных. Однако недостатки у генерации, дополненной поиском, тоже есть.
Основная проблема — несовершенство ответов, получаемых даже после подключения RAG. Пользователи часто жалуются на ограничение контекстного окна, трудности понимания многосоставных запросов и неудовлетворительное качество ответов. Также в некоторых случаях использование технологии может привести к утечке чувствительных данных.
Мария Цвид, Product Owner Beinf.ai by Colobridge:
«RAG все еще не стал идеальным решением, но есть способы, которые приближают его к этому. Среди наиболее очевидных решений будет архитектура RAG, дополненная поиском с использованием SQL, которая поддерживает встроенные функции агрегации данных. Преимущество такого подхода к том, что сами SQL базы имеют больший объем, чем контекстное окно большинства LLM. Другие альтернативы включают GraphRAG (помогает лучше находить взаимосвязи между фрагментами информации) и, агентный RAG».
Другие проблемы, связанные с RAG, включают в себя:
- низкое качество данных — если информация из подключенных источников неточная или неактуальная, такой же ответ с высокой вероятностью получит пользователь;
- ограничение на работу с некоторыми типами данных — наблюдаются трудности с распознаванием графики или сложных многостраничных слайдов (но проблема решается использованием мультимодальных LLM);
- вопросы лицензирования и конфиденциальности — при разработке решения, основанного на RAG, необходимо строго контролировать доступ к таким данным.
Будущее RAG
Подход генерации с дополненным поиском активно используется на практике и в то же время продолжает развиваться и совершенствоваться. Как будущее RAG выглядит глазами аналитиков McKinsey:
- стандартизация — появится больше готовых решений, баз данных и библиотек, что ускорит разработку и развертывание соответствующих ИИ-систем;
- появление RAG на основе агентов — такие системы смогут действовать более автономно, самостоятельно рассуждать и взаимодействовать с себе подобными, более гибко адаптируясь к новым задачам;
- появление LLM, адаптированных для работы с RAG — они смогут более эффективно искать ответы в огромных массивах информации (нечто похожее сейчас реализовано в Perplexity AI).
В целом мы ожидаем не только развития технологии, но и улучшенные возможности для ее масштабирования, но главное — рост влияния на корпоративные приложения, которые уже используют в работе большие языковые модели.
Самое главное о дополненном поиске RAG
- RAG значительно снижает число выдуманных (галлюцинируемых) ответов в генерации ИИ.
- Пользователь видит ссылки на реальные источники, что повышает доверие к ответу.
- Бизнесу не требуется переобучать LLM — истории берутся из обновляемых корпоративных или внешних баз данных.
- RAG ускоряет поиск нужной информации в документации, независимо от формата данных и отдела.
- Решения на RAG позволяют быстрее внедрять интеллектуальные поисковые и справочные системы внутри компаний.
- Система эффективно масштабируется на тысячи документов и многоязычные данные.
- Качество итогового ответа напрямую зависит от актуальности и точности используемых источников.
- Следующий этап развития RAG — агентные архитектуры, гибридный поиск и поддержка мультимодальных данных.
Узнайте, как решения на основе искусственного интеллекта и машинного обучения помогут вашему бизнесу стать более гибким и конкурентоспособным — напишите или позвоните менеджерам Colobridge для консультации.
FAQ
Генерация с дополненным поиском (RAG) — это технология, которая позволяет большим языковым моделям искать ответы не только в своей памяти, но и во внешних источниках. Благодаря этому ИИ может подключаться к базам данных, документам компании или интернету в реальном времени, предоставляя пользователю максимально точную и актуальную информацию.
Внедрение RAG помогает компаниям избежать дорогостоящего переобучения ИИ-моделей под специфические задачи бизнеса. Кроме того, эта технология значительно снижает риски галлюцинаций нейросетей, так как ответы подкрепляются реальными авторитетными источниками, что повышает доверие пользователей.
Генерация с дополненным поиском (RAG) работает с всегда актуальными внешними данными в режиме реального времени и не требует переобучения. Тонкая настройка, в свою очередь, подразумевает переобучение самой модели на специализированных данных, которые со временем могут устаревать.
Процесс начинается с создания базы внешних данных (репозиториев, баз данных, API), к которой ИИ будет обращаться при запросе пользователя. При получении вопроса генерация с дополненным поиском (RAG) находит релевантную информацию в этих источниках, извлекает нужные факты и обогащает ими итоговый ответ с учетом контекста.


