
Автор: Волнянский А.
Неможливо знати все, але важливо знати, де знаходити інформацію в разі потреби — таким принципом керуються великі мовні моделі з RAG. Розповідаємо, як працює цей підхід і як він впливає на якість та повноту відповідей.
- Що таке RAG в ШІ
- Переваги RAG
- Як працює генерація, доповнена пошуком
- Де і як використовувати RAG
- Проблеми та виклики генерації, доповненої пошуком
- Майбутнє RAG
- Найголовніше про доповнений пошук RAG
Що таке RAG в ШІ
RAG (Retrieval-Augmented Generation) — це генерація з доповненою вибіркою або процес пошуку відповіді на запитання користувача до великих мовних моделей (LLM), який супроводжується підключенням до додаткових джерел. Це можуть бути зовнішні бази даних, внутрішні документи компанії, інтернет-статті, наукові та інші джерела даних. Тобто модель RAG дозволяє великій мовній моделі отримувати доступ до інформації, яка спочатку не входила до її навчальної бази. Поява RAG стала важливим етапом розвитку великих мовних моделей, оскільки дозволяє заповнити прогалину у роботі, генеруючи максимально точні відповіді з урахуванням контексту.
Наприклад, ви хочете створити чат-бота з ШІ для магазина цифрової електроніки, щоб автоматизувати роботу служби підтримки. За допомогою LLM ви генеруватимете відповіді лише на загальні питання, що стосуються особливостей конкретних товарів. RAG робить відповіді не універсальними, а максимально релевантними: так користувачі зможуть дізнатися про точний час роботи офлайн-магазинів, терміни доставки товарів, умови гарантії та іншу інформацію, що стосується конкретно вашого бізнесу.

Вперше термін RAG використав Патрік Льюїс у 2020 році у своїй статті для Meta’s AI Research. Тоді він описав, як використовувати генерацію доповненої реальності для завдань обробки природної мови (NLP), які потребують значних знань.
RAG перетворює LLM з універсального засобу пошуку відповідей на більш точне. Тому RAG використовують там, де користувачам необхідні авторитетні, глибокі відповіді, що базуються на конкретних джерелах. Для оцінки релевантності відповідей, отриманих за допомогою RAG, використовують автоматичні метрики (наприклад, BLEU, ROUGE, BERTScore), так і допомогу реальних експертів, які перевіряють частину відповідей вручну.
Поряд із RAG для підвищення точності відповідей LLM використовується тонке налаштування, яке також адаптує велику мовну модель до конкретних сценаріїв використання. Хоча обидва методи розв’язують ту саму проблему, між ними велика різниця.
RAG проти тонкого налаштування у підвищенні точності відповідей LLM:
| Критерій | RAG (Retrieval-Augmented Generation) | Тонке налаштування LLM (Fine-tuning) |
|---|---|---|
| Сутність | Підключення LLM до зовнішніх джерел даних (бази, документи й т. п.) | Перенавчання моделі на спеціалізованих помічених даних |
| Актуалізація даних | Дозволяє використовувати завжди актуальні дані в режимі реального часу | Потребує періодичного перенавчання для оновлення знань |
| Гнучкість | Висока, легко адаптується під різні джерела та типи даних | Обмежена набором даних, на яких було проведене тонке налаштування |
| Швидкість впровадження | Швидше, тому що не потребує перенавчання моделі | Довше, потребує часу на збір та підготовку даних і тренування моделі |
| Особливості використання | Підходить, якщо дані часто змінюються або великий обсяг різноманітної інформації | Ефективна для фіксованих, добре структурованих доменних даних |
| Ризик «галюцинацій» | Менше, тому що відповіді базуються на реальних даних | Вище, якщо модель недостатньо навчена або дані застарілі |
| Приклади сценаріїв | Корпоративні бази знань, підтримка клієнтів, пошук по документах | Чат-боти з глибоким доменним знанням, моделі для аналітики даних і класифікації |
Переваги RAG
RAG дозволяє уникнути великих витрат на адаптацію моделей ШІ для конкретної сфери використання. Якість відповідей при цьому підвищується, але це єдина перевага генерації, доповненої пошуком. Інші можливості цього підходу включають:
- Скорочення ризику галюцинацій. Іноді ШІ-моделі виявляють взаємозв’язки, яких насправді немає, або повертають користувачеві вигадану інформацію. З RAG кількість таких випадків зменшується, оскільки відповіді підкріплюються більш авторитетними та актуальними даними.
- Зростання довіри з боку користувачів. Підвищення точності відповідей і натомість зниження частоти галюцинацій дозволяє завоювати довіру користувачів. Вони також можуть перевірити точність відповіді за джерелами, які надає модель ШІ.
- Ширші можливості. Використання RAG означає, що модель може обробляти більше складних запитів із безлічі достовірних та авторитетних джерел.
- Підвищена безпека даних. Доступ до зовнішніх джерел, які використовує модель при генерації відповідей, доповнених пошуком, може бути відкликаний будь-якої миті.
- Економічний ефект. Компанії, які підключають RAG, уникають витрат на перенавчання моделей, раціональніше використовують людські ресурси та скорочують кількість помилок у відповідях LLM — все разом це дає фінансовий результат.
Як працює генерація, доповнена пошуком
Генерація з доповненою вибіркою починається зі створення бази зовнішніх даних. До них велика мовна модель звертатиметься для того, щоб повертати користувачу більш точні, повні та аргументовані відповіді. Типові джерела — бази даних, API, репозиторії документів різних типів та форматів.
На наступному етапі необхідно забезпечити релевантний пошук. Такий, у якому ШІ чат-бот вибиратиме додаткові джерела, необхідні генерації правильної відповіді. Наприклад, користувач звертається до корпоративної бази даних із питанням, як він може підвищити свою кваліфікацію із компенсацією навчання від компанії. У такому разі чат-боту буде необхідно підключитися до репозиторію внутрішніх документів, знайти там підтвердження можливості такого навчання, а потім до відповідних внутрішніх розпоряджень. І, нарешті, RAG збагачує дані з урахуванням контексту запиту користувача, запитуючи додаткові підказки.
Візуально процес пошуку рішення за допомогою ШІ RAG представлений на зображенні нижче:
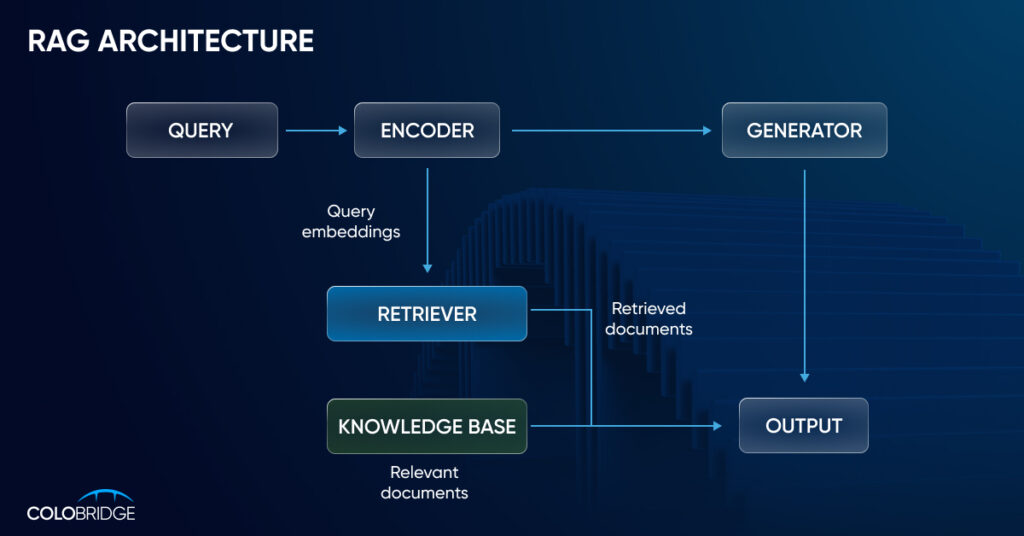
Де і як використовувати RAG
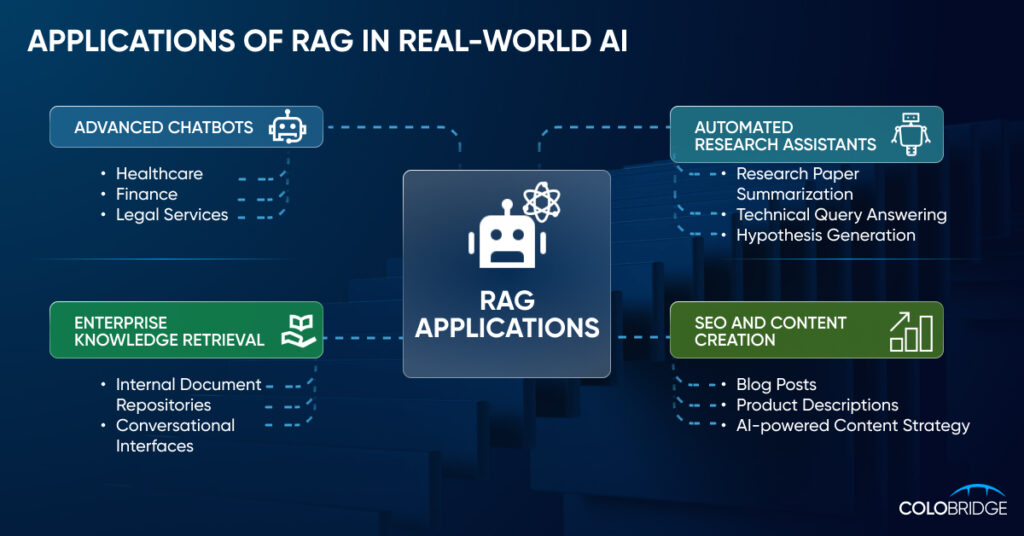
RAG значно розширює можливості використання великих мовних моделей у бізнесі. Ось кілька прикладів, що це демонструють.
Оптимізація роботи маркетингового відділу
RAG допомагає фахівцям з маркетингу генерувати точний, відповідний tone of voice контент, роблячи це швидше та з меншою кількістю помилок. Використовуючи відомості про мікросегменти клієнтської аудиторії, компанія може створювати практично необмежену кількість гіперперсоналізованих email, рекламних оголошень, push-повідомлень на основі актуальних маркетингових матеріалів, бренд-буку, інформації про продукт, запитань клієнтів, запитів на підтримку, історичних та інших відомостей. Крім цього, системи на базі RAG дозволяють отримувати користь з актуальних оглядів ринку, аналітики, трендів, щоб адаптувати маркетингову стратегію під ринок, що швидко змінюється, і краще відповідати очікуванням цільової аудиторії.
Якщо ви бажаєте регулярно створювати правильні та своєчасні повідомлення для кожного мікросегменту аудиторії, скористайтесь нашою платформою для гіперперсоналізації beinf.ai. Це допоможе покращити досвід клієнтів, зробити їх більш лояльними до вашого бренду і зрештою підвищити доходи компанії.
Клієнтська підтримка
Завдяки RAG клієнти зможуть отримувати більш точні та розгорнуті відповіді на свої питання щодо товарів та послуг компанії. Наприклад, точні специфікації продуктів та рекомендації щодо усунення несправностей з офіційної документації до них. Це покращує клієнтський досвід, підвищує довіру до бренду та лояльність, а у довгостроковій перспективі позитивно впливає на прибуток компанії.
Робота з корпоративною базою знань
У великих компаніях працівникам доводиться працювати з великою кількістю внутрішніх документів та посібників. Завдяки RAG співробітники можуть дізнаватися про актуальні зміни в правилах та політиках компанії, чинних соціальних гарантіях або про те, на яких умовах можна перейти на гібридний формат роботи.
Боротьба з шахрайством
Системи на базі RAG автоматизують та прискорюють розслідування випадків шахрайства, а також спрощують обмін оперативною інформацією між підрозділами компанії. Це дозволяє швидше ідентифікувати ризики та приймати відповідні рішення.
Більш ефективна робота з даними
Завдяки RAG можна оптимізувати процедуру пошуку та узгодження даних, що зберігаються у різних підрозділах та системах. Для великої компанії це може бути проблемою: дані часто не синхронізовані, відсутня єдина система пошуку, є дублююча чи навпаки конфліктуюча між собою інформація.
Проблеми та виклики генерації, доповненої пошуком
Своє початкове завдання RAG виконує: ефективність роботи з LLM справді зростає, галюцинації скорочуються, а відповіді виходять за рамки тренувальних даних. Проте недоліки у генерації, доповненої пошуком, також є.
Основна проблема — недосконалість відповідей, які отримують навіть після підключення RAG. Користувачі часто скаржаться на обмеження контекстного вікна, труднощі розуміння багатоскладових запитів та незадовільну якість відповідей. Також у деяких випадках використання технології може призвести до витоку чутливих даних.
Марія Цвид, Product Owner Beinf.ai by Colobridge:
«RAG все ще не став ідеальним рішенням, але є способи, що наближають його до цього. Серед найбільш очевидних рішень буде архітектура RAG, яка доповнена пошуком з використанням SQL, що підтримує вбудовані функції агрегації даних. Перевага такого підходу до того, що самі бази SQL мають більший обсяг, ніж контекстне вікно більшості LLM. Інші альтернативи включають GraphRAG (допомагає краще знаходити взаємозв’язки між фрагментами інформації) та агентний RAG».
Інші проблеми, пов’язані з RAG, включають:
- низька якість даних — якщо інформація з підключених джерел неточна або неактуальна, таку саму відповідь з високою ймовірністю отримає користувач;
- обмеження на роботу з деякими типами даних — спостерігаються труднощі з розпізнаванням графіки або складних слайдів багатосторінкових (але проблема вирішується використанням мультимодальних LLM);
- питання ліцензування та конфіденційності — при розробці рішення на основі RAG необхідно суворо контролювати доступ до таких даних.
Майбутнє RAG
Підхід генерації з доповненим пошуком активно використовується практично і водночас продовжує розвиватися і вдосконалюватися. Як майбутнє RAG виглядає очима аналітиків McKinsey:
- стандартизація — з’явиться більше готових рішень, баз даних та бібліотек, що прискорить розробку та розгортання відповідних ШІ-систем;
- поява RAG на основі агентів — такі системи зможуть діяти автономніше, самостійно міркувати та взаємодіяти з собі подібними, більш гнучко адаптуючись до нових завдань;
- поява LLM, адаптованих до роботи з RAG — вони зможуть ефективніше шукати відповіді у великих масивах інформації (щось подібне зараз реалізовано Perplexity AI).
Загалом ми очікуємо не тільки на розвиток технології, а й на покращені можливості для її масштабування, але головне — зростання впливу на корпоративні застосунки, які вже використовують у роботі великі мовні моделі.
Найголовніше про доповнений пошук RAG
- RAG значно знижує кількість вигаданих (галюцинованих) відповідей у генерації ШІ.
- Користувач бачить посилання реальні джерела, що підвищує довіру до відповіді.
- Бізнесу не потрібно перенавчати LLM — історії беруться з корпоративних або зовнішніх баз даних, що оновлюються.
- RAG прискорює пошук потрібної інформації у документації, незалежно від формату даних та відділу.
- Рішення на RAG дозволяють швидше впроваджувати інтелектуальні пошукові та довідкові системи усередині компаній.
- Система ефективно масштабується на тисячі документів та багатомовні дані.
- Якість підсумкової відповіді безпосередньо залежить від актуальності та точності використовуваних джерел.
- Наступний етап розвитку RAG — агентні архітектури, гібридний пошук та підтримка мультимодальних даних.
Дізнайтеся, як рішення на основі штучного інтелекту та машинного навчання допоможуть вашому бізнесу стати більш гнучким та конкурентоспроможним — напишіть або зателефонуйте менеджерам Colobridge для консультації.




