
Середній та великий бізнес цінує можливість швидко відновити IT-інфраструктуру після збою та повернути працездатність бізнес-додатків й цифрових сервісів. Щоб реалізувати це на практиці, зазвичай необхідні значні матеріальні та людські ресурси. З погляду на складність реалізації та вартість технічного рішення прийнятним для багатьох компаній може виявитися те, що називають Disaster Recovery, або аварійним відновленням.
- Що таке Disaster Recovery
- Способи організації Disaster Recovery
- Характеристики Disaster Recovery
- Кому потрібний Disaster Recovery?
- Чим відрізняються бекапи від Disaster Recovery?
- Технічні рішення Disaster Recovery від Colobridge
Що таке Disaster Recovery
Disaster Recovery (або просто DR) — це набір інструментів та спеціалізоване програмне забезпечення, які вкупі допомагають швидко відновити IT-інфраструктуру, а також дані, роботу всіх систем та сервісів після збою.
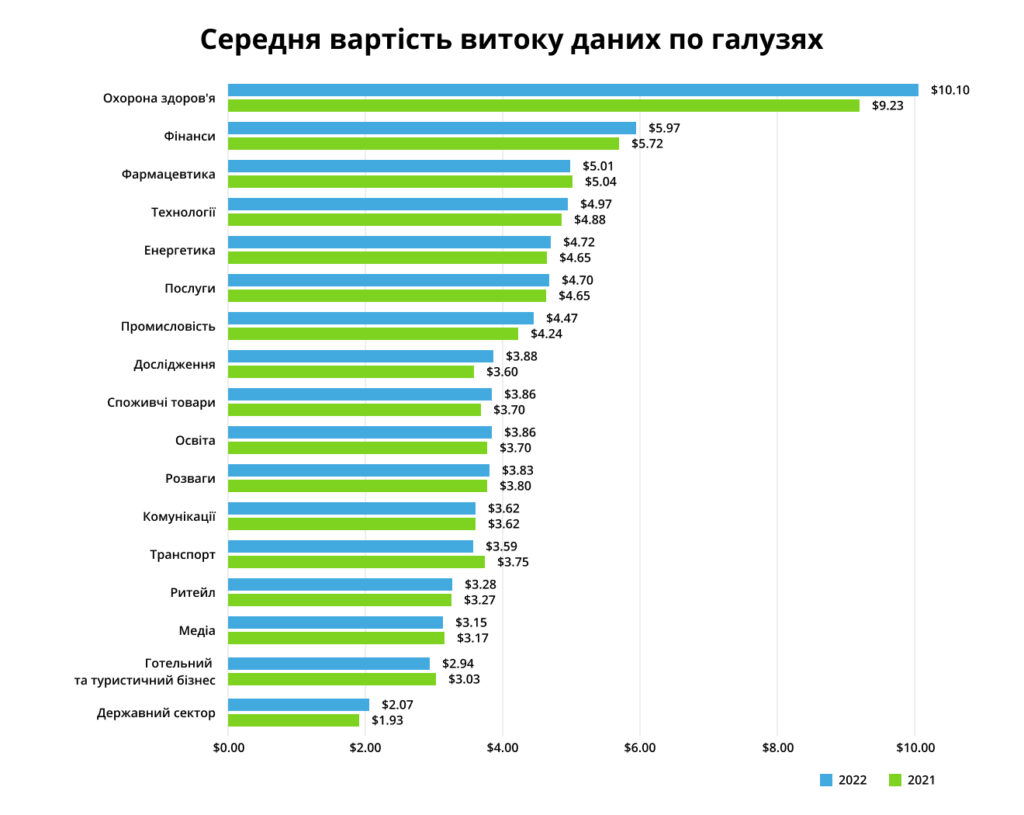
Скільки коштують скомпрометовані або вкрадені дані:
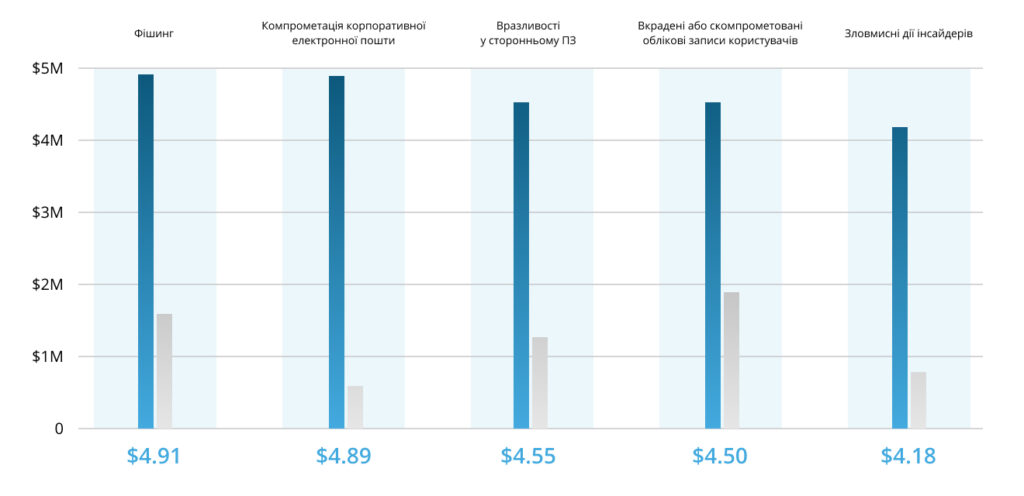
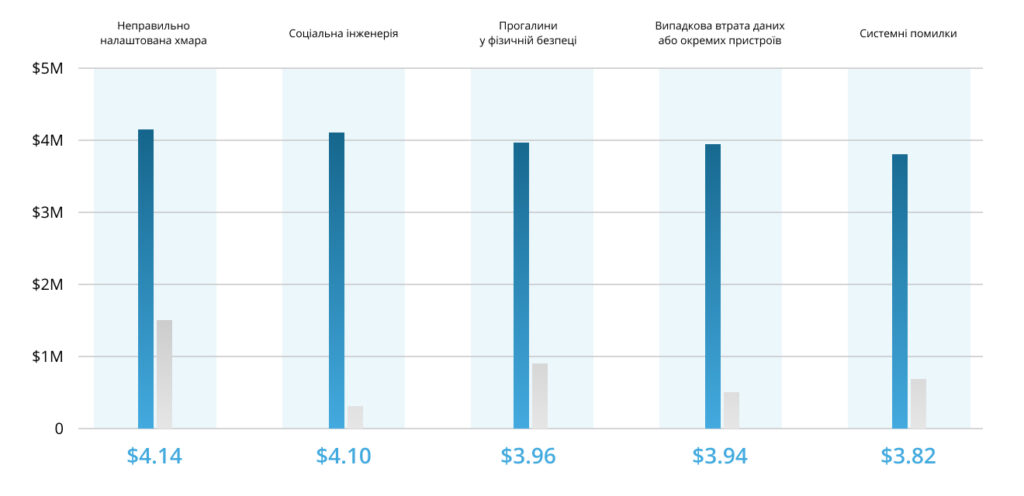
До найчастіших причин збою відносяться: несправність серверного обладнання, вихід з ладу систем зберігання даних, вилучення техніки перевірчими органами (наприклад, для проведення експертизи), крадіжки та диверсії, видалення критично важливих для компанії даних помилково (викликається рядом факторів, включаючи людський), пожежа, потоп чи інше стихійне лихо. Компанії, які зберігають резервні копії даних на одному майданчику з робочою версією, також не захищені від подібних інцидентів, адже при їх настанні разом із майданчиком будуть втрачені і бекапи. У свою чергу, ручне резервування не забезпечує високої швидкості відновлення IT-інфраструктури, може бути надто трудомістким для системного адміністратора і залежить від людського чинника.
Способи організації Disaster Recovery
У бізнесу є щонайменше три способи реалізувати післяаварійне відновлення IT-інфраструктури. Розглянемо кожен із них.
Зробити самостійно на своїй інфраструктурі
Варіант із розгортанням резервного майданчика on-premise, тобто на локальному майданчику — найбільш трудомісткий та дорогий. У цьому випадку компанії фактично доведеться збудувати інфраструктуру, яка дублює основну. А це пов’язане не лише з великими капітальними витратами, а й необхідністю залучення фахівців із вузькими компетенціями.
Побудувати Disaster Recovery на орендованих фізичних серверах
Даний спосіб передбачає дублювання основної ІТ-інфраструктури на фізичних (окремих) серверах, орендованих в іншому дата-центрі, який може знаходитися в іншому місті, регіоні та навіть країні. Це більш відмовостійке рішення, адже шляхом географічного розподілу підвищується надійність зберігання резервних копій — у разі глобальних аварій на зразок пожежі чи повені резервний майданчик не постраждає разом з основною копією даних. З іншого боку, такий підхід має недоліки: відсутність гнучкості як при внесенні змін, так і при оплаті виділених фізичних ресурсів, коли зростуть і капітальні, і операційні витрати.
Розгорнути Disaster Recovery у хмарі
Хмарна інфраструктура, навпаки, приваблює своєю гнучкістю та простим масштабуванням. Тому багато компаній із СМБ-сегменту вважають за краще розгортати резервні копії IT-інфраструктури на хмарних платформах. Великий плюс у тому, що у хмарі можна прозоро керувати обсягом ресурсів, необхідних для виконання Disaster Recovery: резервувати продуктивне сховище для копії IT-інфраструктури разом із пулом необхідних потужностей для її розгортання або користуватися лише сховищем, а віртуальні ресурси отримати за фактом (втім, без гарантій з боку провайдера, що необхідні ресурси будуть доступні в потрібний момент).

Disaster Recovery as a Service
DRaaS (Disaster Recovery as a Service) є післяаварійним відновленням за моделлю «як послуга». У разі серйозного збою сисадмін за лічені хвилини зможе розгорнути у хмарі робочу копію IT-інфраструктури на резервному майданчику Disaster Recovery, наданому провайдером. Одночасно на основному майданчику розпочнуться відновлювальні роботи відповідно до заздалегідь розробленого плану післяаварійного відновлення (Disaster Recovery Plan). Іншими словами, сервісна модель Disaster Recovery — клонування інфраструктури в хмару у разі настання аварії та до її усунення на основному майданчику.
Головні переваги DRaaS перед іншими способами реалізації Disaster Recovery:
- швидке відновлення інфраструктури даних;
- оптимізація витрат на післяаварійне відновлення ІТ-інфраструктури;
- можливість реплікації «гарячих даних» як реального часу;
- гнучкі умови ліцензування спеціалізованого ПЗ провідних вендорів;
- після відновлення з архіву дані зберігають консистентність;
- просте масштабування рішення у хмарі.
Характеристики Disaster Recovery
На терміни та вартість післяаварійного відновлення впливають дві ключові характеристики — RTO та RPO. Що вони означають та на що впливають?
RTO
RTO (Recovery time objective, або «цільовий час відновлення») — це часовий проміжок, протягом якого IT-інфраструктура залишатиметься недоступною у разі аварії чи іншого інциденту. Допустиме значення RTO визначається специфікою та потребами бізнес. Фактично це час, протягом якого цифрові послуги компанії можуть простоювати без відчутних наслідків. Чим менше значення RTO, тим дорожче обійдеться послуга Disaster Recovery.
RPO
RPO (Recovery point objective, або «цільова точка відновлення») — це часовий проміжок, дані за який можуть бути втрачені без серйозних наслідків. Наприклад, для RPO, що дорівнює одній годині, резервне копіювання виконується чітко один раз на 60 хвилин. Так само й IT-інфраструктура після відновлення повернеться до того стану, в якому була за годину або менше до аварійного інциденту (на практиці багато залежить від того, коли саме стався збій — через 5, 15, 30 або 55 хвилин після створення копії). Чим меншим є значення RPO, тим частіше виконується резервування IT-інфраструктури й тим дорожче коштує DR-сервіс відновлення.
Визначити оптимальні значення RTO та RPO — означає знайти компроміс між вартістю вирішення післяаварійного відновлення та серйозністю наслідків простою для бізнесу.
Думка експерта Colobridge:
«Щоб визначити оптимальні параметри RTO/RPO, достатньо відповісти на два основні питання:
— чи будуть для вашого бізнесу актуальними дані тижневої/місячної давності?
— втрату даних за який період ваш бізнес може пережити? (наприклад, за годину, добу, тиждень або інший час).
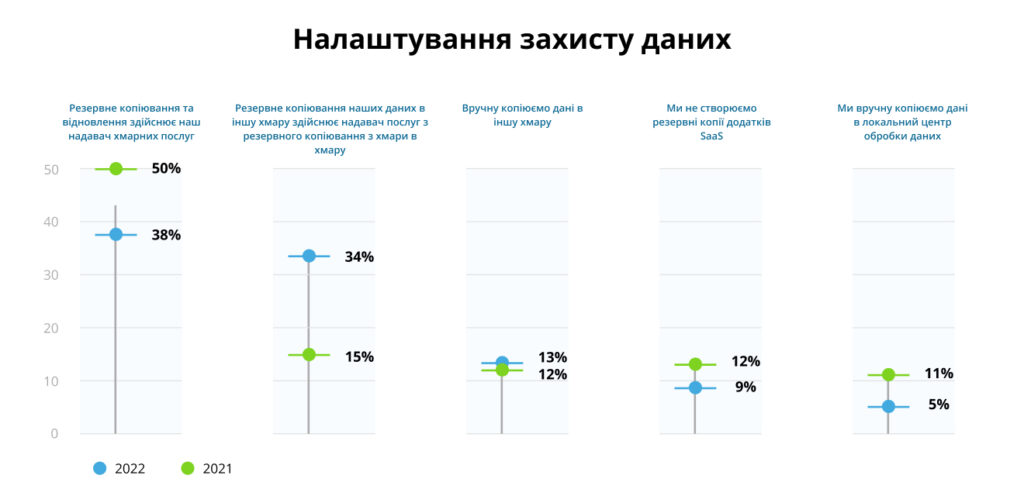
Згідно з нашою статистикою, найчастіше клієнти обирають варіант робити резервне копіювання один раз на добу і переважно в нічний час — коли їх IT-системи найменш навантажені, а також зберігають останні сім архівних копій. Тоді максимальний обсяг даних, що теоретично може втратити бізнес, відповідає одному робочому дню. У такому сценарії розміри репозиторію в 1,3-1,4 рази перевищуватимуть обсяг зайнятих даних. Наприклад, віртуальна машина розмірами 100 ГБ займе у репозиторії до 140 ГБ.
Кому потрібний Disaster Recovery?
Зазвичай до послуги Disaster Recovery вдаються компанії, які прагнуть додатково захистити свою IT-інфраструктуру і готові виділити певну частку бюджету на IT. Ми в Colobridge рекомендуємо послугу Disaster Recovery as a Service насамперед для корпоративного сектору — зокрема, клієнтам із фінансового та банківського сектору, інтернет-магазинам, аграрним компаніям та будь-яким іншим, у яких від доступності та стабільної роботи їх цифрових сервісів безпосередньо залежать доходи та репутація бізнесу.
Disaster Recovery у банківській сфері
Банки та інші фінансові установи дуже чутливі до простоїв, а втрата даних навіть за порівняно невеликий проміжок часу може призвести до серйозних наслідків як для банку, так і для його клієнтів. Тому саме в банках та компаніях fintech-сфери заведено оперувати мінімальними значеннями RTO та RPO, оскільки у разі збою витрати на відновлення IT-інфраструктури будуть меншими, ніж потенційні збитки від простою.
Disaster Recovery у сфері обслуговування
Тут ситуація із зупинкою IT-сервісів та недоступністю даних може бути не такою критичною, як у банку, проте на практиці все залежить від розмірів бізнесу. Для служби доставлення вантажів із сотнями відділень по всій країні вигідніше оплатити сервіс Disaster Recovery та застрахувати себе від форс-мажорних ситуацій, коли збитки у кілька разів перевищуватимуть витрати на цю послугу. Але для служби доставлення харчових продуктів у місті-стотисячнику залишитися без підключення до основного сервера на кілька годин буде менш критичною подією, хоча й спричинить як матеріальні збитки, так і репутаційні втрати.
Думка експерта Colobridge:
«Ми можемо говорити лише про умовні відмінності використання Disaster Recovery у сфері обслуговування — на практиці насправді багато залежить від швидкості виконання бізнес-операцій. Навіть серед компаній, що надають послуги експрес-доставлення вантажів, ситуація може відчутно відрізнятися. Так, одні компанії серйозно не постраждають після простою тривалістю в кілька годин, для інших за тих же обставин збитки будуть виражатися в шестизначних цифрах, оскільки склади миттєво переповняться, порушиться логістика, простоюватимуть тисячі співробітників».
Чим відрізняються бекапи від Disaster Recovery?
Сервіси створення бекапів (наприклад, BaaS — Backup as a Service) передбачають використання хмарного репозиторію тільки для зберігання архівних копій, тоді як з DRaaS клієнт отримує сервіс дзеркалювання у хмарі провайдера IT-інфраструктури та можливість запускати віртуальні сервери в автоматичному режимі, якщо виникне аварійна ситуація.
DRaaS має значну перевагу перед BaaS: він дозволяє швидко включити необхідну точку, щоб як велика, так і невелика компанія якнайшвидше і бажано непомітно для клієнтів повернулися до нормального режиму роботи. Це стає можливим завдяки тому, що дані розміщуються на продуктивному сховищі замість того, щоб зберігатися в заархівованому вигляді, як у випадку з BaaS. Крім того, хмарний провайдер Disaster Recovery as Service пропонує більше налаштувань, можливість гнучкого керування частотою створення (за розкладом) та параметрами відновлення віртуальних машин із резервних копій.
Реплікація IT-інфраструктури у хмару за допомогою DRaaS зовсім не означає відмову від традиційних бекапів. Клієнти можуть користуватися цими двома інструментами одночасно: «гарячі дані» копіювати раз на кілька годин і зберігати протягом двох-трьох днів, а копії «негарячих систем» робити щодня та зберігати їх, наприклад, тиждень. Налаштування інфраструктури в концепції Disaster Recovery компанія робить відповідною під свої вимоги.
Технічні рішення Disaster Recovery від Colobridge
Послуга DRaaS, доступна на технологічній платформі Colobridge, дає змогу швидко відновити віртуальні сервери у власний хмарний репозиторій, який фактично розгорнуть у двох сертифікованих німецьких дата-центрах рівня Tier III/Tier III+. Ви можете самостійно вибрати кількість точок відновлення та частоту їх створення чи скористатися допомогою наших експертів. Вони дадуть розгорнуту консультацію з урахуванням специфіки бізнес-навантажень та бюджету на реалізацію стратегії Disaster Recovery. В рамках послуги DRaaS можна орендувати будь-яку кількість віртуальних машин та будь-який об’єм обчислювальних ресурсів, а згодом масштабувати рішення зі зростанням бізнесу.
Щоб дізнатися більше про DRaaS на платформі Colobridge, отримати рекомендації щодо опцій частоти створення копій та глибини архіву, а також допомогу у складанні плану аварійного відновлення даних (плану бекапів), а також виробити алгоритм дій, звертайтесь до фахівців нашої компанії — ми надамо всю необхідну інформацію, а за підсумками протестуємо та верифікуємо Disaster Recovery Plan відповідно до вимог бізнесу.




