
Author: Talabuyev Y.
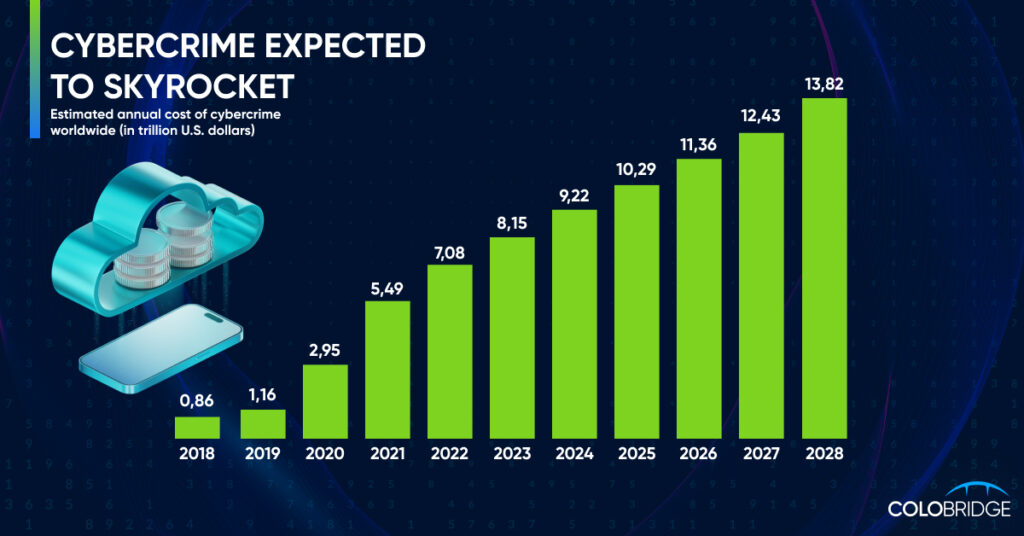
Let’s talk about something critically important for every business today: cybersecurity incidents. These are no longer hypothetical threats—they’re happening all the time. Last year alone, 75% of companies faced ransomware attacks! That’s why creating an incident response plan isn’t just a “nice idea”—it’s a way to survive in the digital world.
- What is an Incident Response Plan (IRP)?
- The Foundation of Your Cybersecurity Strategy
- Core Phases of Incident Response
- Metrics, Documentation, Testing, and Compliance
- Tools and Technologies: Arm Yourself for Defense
- Common Pitfalls and Keys to Success
- Cloud Incident Response Considerations
- Wrap-Up: The Perfect Incident Response Plan
- FAQ: Answers to Common Incident Response Questions
What is an Incident Response Plan (IRP)?
Here’s the academic definition:
An Incident Response Plan (IRP) is a clear, structured document that outlines how your organization should act during a cyberattack. This process includes identifying threats, containing them, mitigating damage, and restoring system operations. The goal is not just to address the aftermath but to minimize losses and prevent future attacks.
And here’s the IRP in simple terms:
An IRP is a clear, step-by-step plan for what to do if a cyberattack occurs: how to detect it, stop it, address the consequences, and protect against future incidents.
Why it matters: A robust plan helps you handle incidents quickly—reducing chaos and losses, minimizing downtime, protecting critical customer data, preserving your company’s reputation, ensuring business continuity, and helping you comply with legal requirements. In other words, it’s like a controlled landing compared to a crash.
This guide, based on expert recommendations and best practices, will help you create an effective incident response plan and protect your business.
The Foundation of Your Cybersecurity Strategy
Let’s explore the core principles (or pillars) that form the backbone of an incident response strategy.
1. Developing Your Incident Response Plan
An IRP is your documented strategy for tackling cybersecurity incidents and a dynamic tool for faster, more effective responses.
Pro tip: Update your IRP at least annually and after major business or tech changes. An outdated plan is nearly as bad as none at all!
Key elements of an IRP:
- Purpose and Scope: Define its goals and the types of incidents it covers (from malware to major data breaches). Align it with your business objectives and identify critical systems and data to protect. Clear boundaries prevent confusion later.
- Customization is key: Your IRP must fit your company. Generic templates or recycled plans won’t work. Your business structure, tech stack (cloud vs. on-premises differs), risks, and compliance needs (e.g., HIPAA, GDPR, PCI DSS) are unique. Use frameworks like NIST or SANS as a starting point, but tailor them to your needs.
Core sections of a strong IRP:
- Basics: Plan objectives, scope, and formal approval.
- Team A: Incident Response Team (IRT) members, roles, and reporting structure.
- Definitions: Clear explanations of terms (data classification, incident severity levels, etc.).
- Action Plan: Step-by-step incident response process.
- Response Scenarios: Tailored playbooks for specific threats (ransomware, phishing, etc.).
- Communication Strategy: Internal and external communication plans for incidents.
- Implementation: How you’ll test the plan.
- Tracking: Version control—who changed what and when.
- Mission Alignment: Ensure the plan supports your company’s core goals.
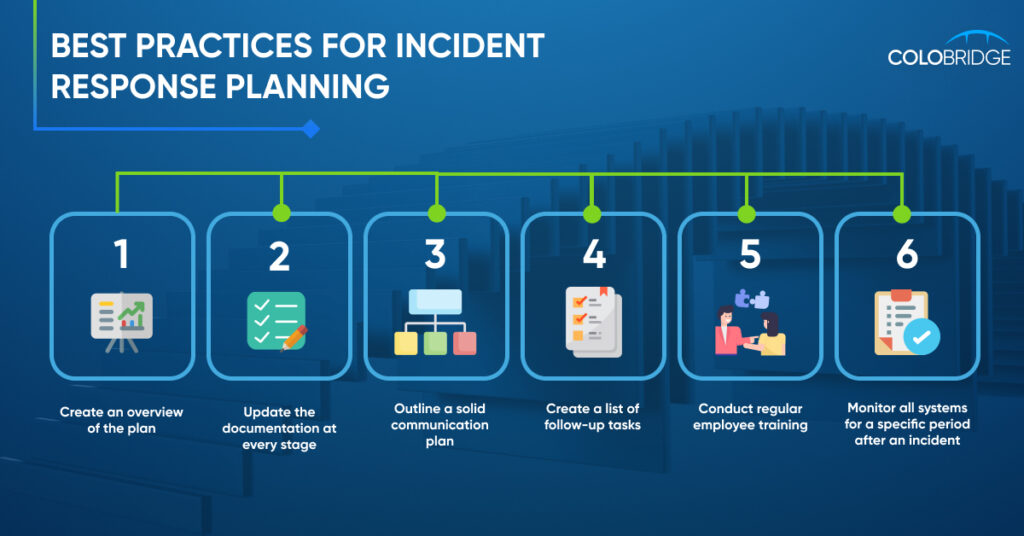
2. The Incident Response Process—Your Playbook
This is where theory meets action: a clear sequence of steps for your team during an incident. It should cover all involved teams (security, IT, legal, PR) and define responsibilities clearly—a RACI matrix works well here.
RACI explained: A simple way to assign roles and responsibilities for tasks or projects:

This ensures clarity and avoids confusion.
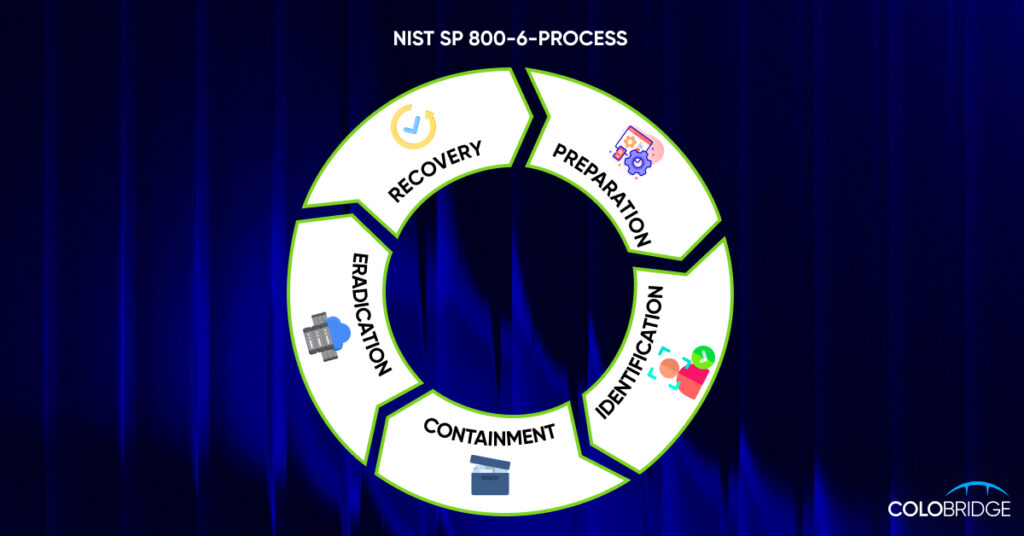
Popular frameworks like NIST (SP 800-61) outline four stages, but many use six phases:
- Preparation: Deploy security tools (SIEM, EDR, etc.), train your team, and draft the IRP.
- Identification & Analysis: Spot suspicious activity (via monitoring tools or employees) and investigate its scope, severity, and impact.
- Containment: Isolate the threat to prevent further damage (e.g., disconnect devices, block malicious traffic).
- Eradication: Identify and eliminate the root cause (remove malware, patch vulnerabilities, or rebuild systems).
- Recovery: Restore systems and data from backups, ensuring secure functionality.
- Post-Incident Analysis/Lessons Learned: Review what worked, what didn’t, and why. Document lessons to prevent future incidents.
3. Assembling Your Incident Response Team (IRT)
Your Computer Security Incident Response Team (CSIRT or IRT) drives the creation and execution of the plan. Include IT, security experts, legal, operations, and PR/communications leaders.
What matters:
- Roles & Responsibilities: Everyone must know their role, from first responder to decision-maker. Assign one owner per task.
- Hierarchy & Escalation: Define who makes decisions, who gets notified first, and how quickly escalation occurs based on threat severity.
- Gather frontline insights: Consult your CISO, security managers, SOC analysts, network admins, and helpdesk for practical input. Their real-world experience ensures a workable plan.
Core Phases of Incident Response
Preparation
Build a strong foundation before disaster strikes. Key steps:
- Tech arsenal: Deploy and configure firewalls, SIEM, antivirus/EDR, vulnerability scanners, and backup systems. Consider incident response software, SOAR platforms, or managed services. Use cloud-specific automation tools if applicable.
- Train your team: Conduct regular cybersecurity training and phishing simulations to make employees part of your defense.
- Backup regularly: Ensure backups are frequent, tested, and ideally stored immutably.
- Implement security principles: Adopt zero trust, least privilege, network segmentation, and multifactor authentication (MFA).
- Audit assets: Identify critical systems/data and assess their business impact if compromised.
- Assess risks: Pinpoint specific threats and vulnerabilities through regular risk assessments.
- Patch and harden: Keep systems updated and configurations secure.
- Document your environment: Maintain an up-to-date asset inventory and network diagrams.
Identification & Analysis
How do you know something’s wrong? This phase focuses on spotting and assessing issues.
- Continuous monitoring: Track networks, endpoints, and logs using incident detection tools, including cloud monitoring.
- Smart alerts: Configure alerts for suspicious activity.
- Triage: Quickly assess alerts, prioritize based on incident severity, and use frameworks like MITRE ATT&CK® or Cyber Kill Chain.
- Investigate: Dig into the “what, where, when, who, and how.”
- Document: Log and analyze findings thoroughly.
Containment
You’ve spotted the issue—now stop it from spreading.
- Isolate systems: Disconnect affected devices from the network.
- Block access: Disable compromised accounts and reset passwords.
- Preserve evidence: Analyze security logs.
- Stay vigilant: Attackers may react to your actions, so monitor closely.
Eradication
Eliminate the threat and fix the root cause.
- Identify and remove: Find the entry point (malware, vulnerability) and close it.
- Clean and patch: Remove malware, patch vulnerabilities, or rebuild systems from a clean state.
- Deep audit: Ensure no hidden backdoors remain.
Recovery
Restore operations quickly but carefully to ensure business continuity.
- Restore systems: Bring systems/data online using backups or configurations.
- Collaborate: Work with IT for seamless recovery.
- Verify security: Ensure restored systems are patched, secure, and malware-free.
Post-Incident Analysis/Lessons Learned
The crisis is over, but learning begins. This is how you improve.
- Conduct a blame-free review: Analyze what worked, what didn’t, and why.
- Dig deep: Collect data, identify root causes, and assess full impact. A SWOT analysis can help.
- Document findings: Record lessons learned and share with the team.
- Create an action plan: Assign tasks with owners and deadlines to address weaknesses.
- Track metrics: Measure improvements in incident response metrics (MTTD, MTTR).
Metrics, Documentation, Testing, and Compliance
How Are You Doing?
Use key performance indicators to measure your incident response process objectively.
Examples:
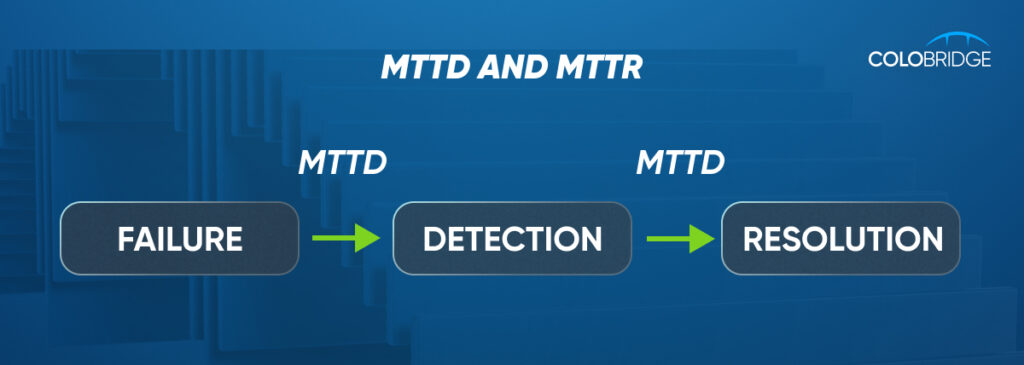
- Mean Time to Detect (MTTD): How fast do you spot issues?
- Mean Time to Respond/Resolve (MTTR): How quickly do you neutralize them?
- Containment effectiveness.
- Cost/duration of downtime.
- Number of improvements from lessons learned.
These metrics track progress, justify resources, and highlight areas for improvement.
Documentation: Your Incident Response Library
Keep everything organized: IRP, process diagrams, response playbooks, communication templates, forms, and knowledge base articles. Use centralized storage.
Stakeholder Engagement and Compliance
Involve IT, security, legal, operations, and HR in plan creation. Align with business priorities, compliance requirements (SOC 2, ISO 27001, GDPR), and critical data hierarchies for a realistic, supported plan.
Testing and Drills: Practice Under Pressure
An untested plan is just theory. So:
- Run training and simulations: Test scenarios like ransomware or data breaches.
- Identify gaps: Fix broken procedures, clarify roles, and update tools.
- Build confidence: Practice ensures calm, effective responses under pressure.
Industry Standards and Frameworks
Use established best practices like NIST SP 800-61, ISO 27001, SANS, CIS Controls, or MITRE ATT&CK® for robust guidance.
Tools and Technologies: Arm Yourself for Defense
Choose incident response tools that match your tech stack and infrastructure (cloud, hybrid, or on-premises). Options include SIEM, EDR, SOAR, vulnerability scanners, and AI-based platforms. These automate key response phases, saving time and reducing human error.
Common Pitfalls and Keys to Success
Success Factors:
- Secure stakeholder support.
- Tailor and regularly test your IRP.
- Build a robust communication plan.
- Measure performance and maintain documentation.
Pitfalls to Avoid:
- Using generic, untested templates.
- Creating “check-the-box” plans for audits only.
- Unclear responsibilities or poor team coordination.
- Confusing incident response with disaster recovery—ensure both work together.
Cloud Incident Response Considerations
Cloud environments require specific adjustments.
- Shared responsibility model: Understand your provider’s capabilities and limits.
- Cloud logging and monitoring: Use cloud-native tools.
- Adapt procedures: Tailor responses to the cloud’s dynamic nature.
Wrap-Up: The Perfect Incident Response Plan
Ready to start? Here’s the recap:
- Plan first: Create a tailored, documented IRP that fits your needs.
- Process matters: Define steps (Preparation, Identification, Containment, Eradication, Recovery, Lessons Learned) and roles.
- Teamwork wins: Assemble an IRT with clear responsibilities.
- Preparation is half the battle: Invest in tools, training, and backups.
- Test and improve: Regularly train, learn from mistakes, and keep the plan current.
Focusing on these areas—plan creation, process definition, team empowerment, preparation, and testing—will significantly boost your ability to handle cyber threats. Good luck!
FAQ: Answers to Common Incident Response Questions
What are the six phases of incident response?
Think of it like this: 1. Prepare. 2. Spot and analyze the issue. 3. Contain the spread. 4. Eliminate the problem. 5. Restore systems and data. 6. Learn from it.
How do you create an effective IRP?
No magic wand, but key steps include assembling the right team, understanding your risks, defining clear actions, planning communications, and regularly training, testing, and updating. Ensure it’s tailored to your business—no copying!
What does a CSIRT do?
Your CSIRT (or IRT) is the command center during an incident, handling response, investigation, communications, plan execution, and improvements.
Is cloud incident response different?
Yes, it’s unique! You deal with a cloud provider’s infrastructure and shared responsibility. Data may be distributed, requiring cloud-specific tools and skills. Adapt your approach if it’s built for on-premises.
What tools are essential?
You need monitoring/detection tools (SIEM, EDR), firewalls, vulnerability scanners, robust backup/recovery solutions, and automation platforms (SOAR).
Why is incident response planning critical?
Bad things will happen! Planning turns panic into swift, coordinated action, saving money, reducing downtime, protecting reputation, ensuring business continuity, and meeting legal requirements.
What are the biggest IRP mistakes?
Using generic, untested plans; vague role assignments; poor crisis communication; failing to learn from incidents; and assuming backups work without testing.
How do you test an IRP?
Run hands-on drills and tabletop exercises. Simulate scenarios to identify weaknesses, then fix procedures, roles, or tools.
What’s NIST SP 800-61?
It’s NIST’s gold standard for handling computer security incidents, offering a detailed framework for your IRP.
Does cyber threat intelligence help?
Absolutely! Knowing threats, attackers, and their methods improves preparation and response. Threat intelligence makes your approach proactive.
Who should be on the IRT?
Include IT, security, legal, PR, operations, and other stakeholders, especially if incidents impact business risks or reputation.
What’s the difference between a security “event” and an “incident”?
An event is something that happens (e.g., a failed login). An incident causes harm or threatens system/data confidentiality, integrity, or availability, requiring a formal response.
How much does incident response cost?
Costs vary based on incident severity, resolution time, fines, business losses, and external services. Good planning reduces these costs significantly.
What about notifying people after a data breach? Legal aspects?
This depends on laws (GDPR, HIPAA, etc.) and customer locations. Your legal team should advise on notification obligations for regulators and affected individuals.
Can AI help with incident response?
Yes! SOAR platforms and machine learning speed up threat analysis and automate responses.
What are MTTD and MTTR?
Key metrics: MTTD (Mean Time to Detect) measures how fast you spot issues; MTTR (Mean Time to Respond/Resolve) measures how quickly you fix them. Lower is better.
Why bother with post-incident reviews?
They’re critical for learning and improving, reducing repeat mistakes. It’s the foundation of the lessons-learned phase.
How do you respond to phishing?
Your IRP should outline steps: isolate the user/device, reset credentials, analyze the phishing email, block related indicators, check for further compromise, and learn from it.
What are the key steps for ransomware recovery?
Identify and isolate affected systems. Restore from backups (preferred) or decrypt if a key is available (rare and risky). Never rely on paying the ransom.




