Disaster Recovery (аварийное восстановление) – ключевой элемент защиты бизнеса в случае сбоев. Оно помогает компаниям минимизировать потери данных и возобновить работу за минимальное время.
- Что такое Disaster Recovery
- Способы организации Disaster Recovery
- Характеристики Disaster Recovery
- Кому нужен Disaster Recovery?
- Чем отличаются бэкапы от Disaster Recovery?
- Технические решения Disaster Recovery от Colobridge
Что такое Disaster Recovery
Disaster Recovery (или просто DP) представляет собой набор инструментов и специализированное программное обеспечение, которые помогают быстро восстановить IT-инфраструктуру, а также возобновить данные, работу всех систем и сервисов после сбоя.
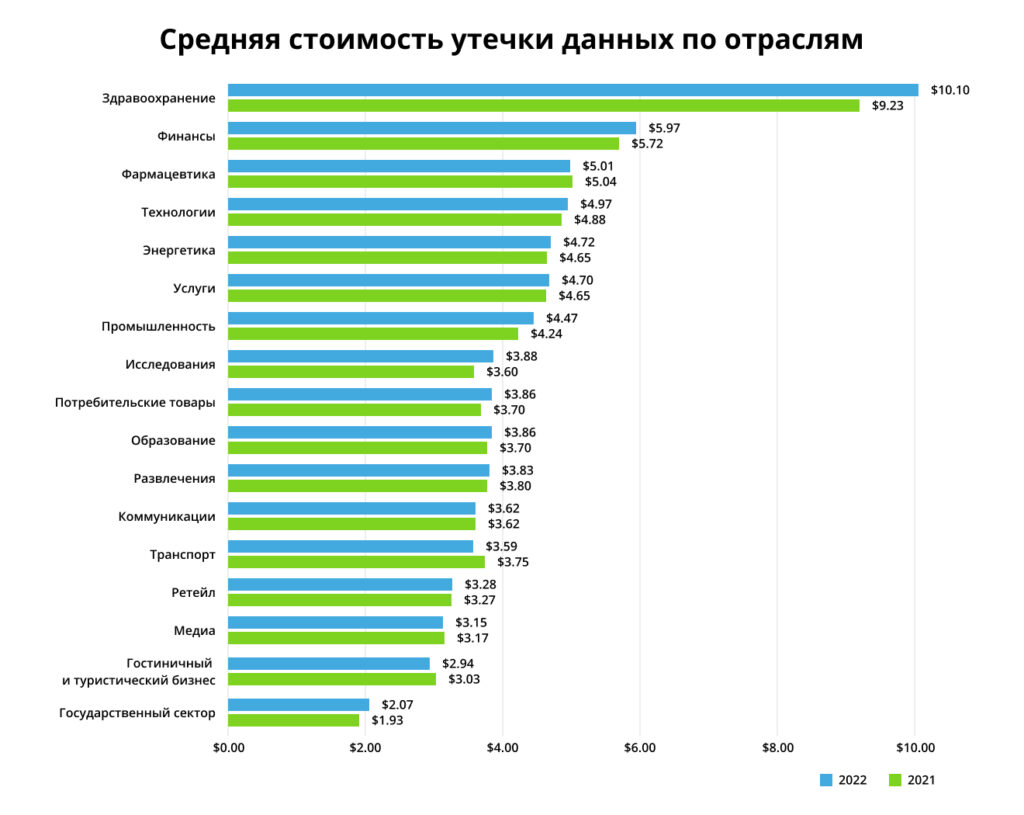
Во сколько обходятся скомпрометированные или украденные данные:
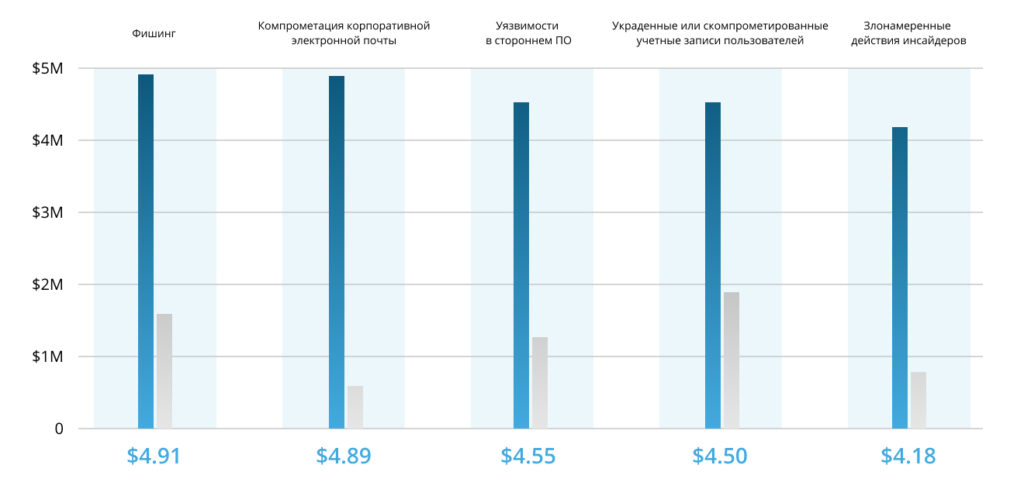
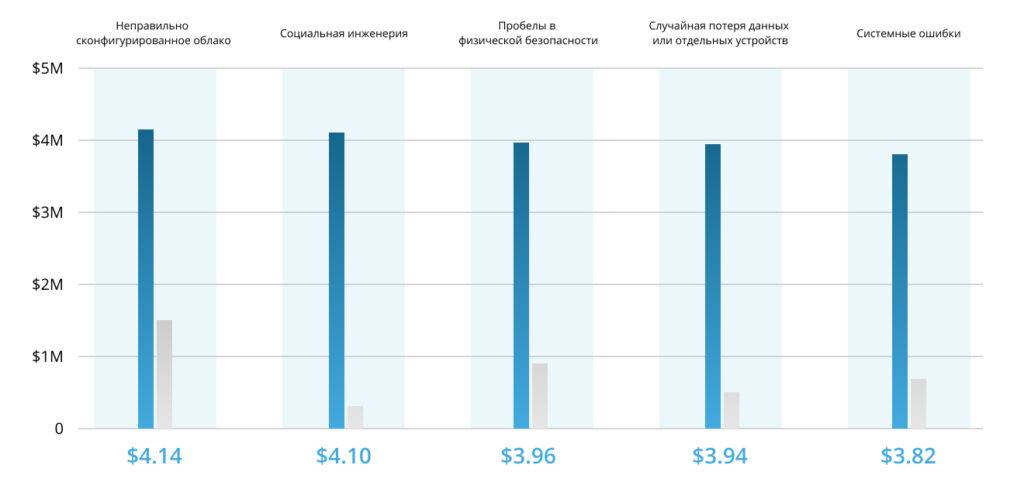
К наиболее частым причинам сбоя относятся: поломка серверного оборудования, выход из строя систем хранения данных, изъятие техники контролирующими органами (например, для проведения экспертизы), кражи и диверсии, удаление критически важных для компании данных по ошибке (вызывается рядом факторов, включая человеческий), пожар, потоп или другое стихийное бедствие. Компании, которые хранят резервные копии данных на одной площадке с рабочей версией также не защищены от подобных инцидентов, ведь при их наступлении вместе с площадкой будут потеряны и бэкапы. В свою очередь, ручное резервирование не обеспечивает высокой скорости восстановления IT-инфраструктуры, может быть слишком трудоемким для системного администратора и сильно зависит от человеческого фактора.
Способы организации Disaster Recovery
У бизнеса есть минимум три способа реализовать послеаварийное восстановление IT-инфраструктуры. Рассмотрим каждый из них.
Сделать самостоятельно на своей инфраструктуре
Вариант с развертыванием резервной площадке on-premise, то есть на локальной площадке — самый трудоемкий и затратный. В этом случае компании фактически придется построить инфраструктуру, которая дублирует основную. А это, в свою очередь, сопряжено не только с крупными капитальными затратами, но и необходимостью привлечения специалистов с узкими компетенциями.
Построить Disaster Recovery на арендованных физических серверах
Данный способ предполагает дублирование основной IT-инфраструктуры на физических (отдельных) серверах, арендованных в другом дата-центре, который может находиться в другом городе, регионе и даже стране. Это более отказоустойчивое решение, ведь за счет географического распределения повышается надежность хранения резервных копий — в случае глобальных аварий вроде пожара или наводнения резервная площадка не пострадает вместе с основной копией данных. С другой стороны, у такого подхода есть недостатки: отсутствие гибкости как при внесении изменений, так и при оплате выделенных физических ресурсов, когда вырастут и капитальные, и операционные расходы.
Развернуть Disaster Recovery в облаке
Облачная инфраструктура, наоборот, привлекает своей гибкостью и простым масштабированием. Поэтому многие компании из СМБ-сегмента предпочитают разворачивать резервные копии IT-инфраструктуры на облачных платформах. Большой плюс в том, что в облаке можно прозрачно управлять объемом ресурсов, необходимых для выполнения Disaster Recovery: резервировать продуктивное хранилище для копии IT-инфраструктуры вместе с пулом необходимых мощностей для ее разворачивания или пользоваться только хранилищем, а виртуальные ресурсы получить по факту (впрочем, без гарантий со стороны провайдера, что нужны ресурсы будут доступны в нужный момент).

Disaster Recovery as a Service
DRaaS (Disaster Recovery as a Service) представляет послеаварийное восстановление по модели «как услуга». В случае серьезного сбоя сисадмин за считанные минуты сможет развернуть в облаке рабочую копию IT-инфраструктуры на резервной площадке Disaster Recovery, предоставленной провайдером. Одновременно на основной площадке начнутся восстановительные работы в соответствии с заранее разработанным планом послеаварийного восстановления (Disaster Recovery Plan). Другими словами, сервисная модель Disaster Recovery — клонирование инфраструктуры в облако в случае наступления аварии и до полного ее устранения на основной площадке.
Главные преимущества DRaaS перед другими способами реализации Disaster Recovery:
- быстрое восстановление инфраструктуры данных;
- оптимизация затрат на послеаварийное восстановление IT-инфраструктуры;
- возможность репликации «горячих данных» в режиме реального времени;
- гибкие условия лицензирования специализированного ПО ведущих вендоров;
- после восстановления из архива данные сохраняют консистентность;
- простое масштабирование решения в облаке.
Характеристики Disaster Recovery
На сроки и стоимость послеаварийного восстановления влияют две ключевые характеристики — RTO и RPO. Что они означают и на что влияют?
RTO
RTO (Recovery time objective, или «целевое время восстановления») — это временной промежуток, в течение которого IT-инфраструктура будет оставаться недоступной в случае аварии или другого инцидента. Допустимое значение RTO определяется спецификой и потребностями бизнес. Фактически это время, которое цифровые сервисы компании могут простаивать без ощутимых последствий. Чем меньше значение RTO, тем дороже обойдется услуга Disaster Recovery.
RPO
RPO (Recovery point objective, или «целевая точка восстановления») — это временной промежуток, данные за который могут быть потеряны без серьезных последствий. Например, для RPO, равного одному часу, резервное копирование выполняется строго один раз в 60 минут. Точно также и IT-инфраструктура после восстановления будет возвращена в то состояние, в котором была за час или менее до аварийного инцидента (на практике многое зависит от того, когда именно случился сбой — через 5, 15, 30 или же 55 минут после создания копии). Чем меньше значение RPO, тем чаще выполняется резервирование IT-инфраструктуры и, соответственно, тем дороже стоит DR-сервис восстановления. Определить оптимальные значения RTO и RPO означает найти компромисс между стоимостью решения послеаварийного восстановления и серьезностью последствий простоя для бизнеса.
Мнение эксперта Colobridge:
«Чтобы определить оптимальные параметры RTO/RPO, достаточно ответить на два основных вопроса:
— будут ли для вашего бизнеса актуальными данные недельной/месячной давности?
— потерю данных за какой период времени ваш бизнес может пережить? (например, за час, сутки, неделю или другой срок).
Согласно нашей статистике чаще всего клиенты выбирают вариант делать резервное копирование один раз в сутки и предпочтительно в ночные часы — когда их IT-системы наименее нагружены, а также хранят последние семь точек восстановления. Тогда максимальный объем данных, который теоретически может потерять бизнес, соответствует одному рабочем дню. В таком сценарии размеры репозитория будут в 1,3-1,4 раза превышать объем занятых данных. Например, виртуальная машина размерами 100 ГБ займет в репозитории до 140 ГБ.
Кому нужен Disaster Recovery?
Обычно к услуге Disaster Recovery прибегают компании, которые стремятся дополнительно защитить свою IT-инфраструктуру и готовы выделить на это определенную долю бюджета на IT. Мы в Colobridge рекомендуем услугу Disaster Recovery as a Service прежде всего для корпоративного сектора — в частности, клиентам из финансового и банковского сектора, интернет-магазинам, аграрным компаниям и любым другим, в которых от доступности и стабильной работы их цифровых сервисов напрямую зависят доходы и репутация бизнеса.
Disaster Recovery в банковской сфере
Банки и другие финансовые учреждения очень чувствительны к простоям, а потеря данных даже за сравнительно небольшой промежуток времени может обернуться серьезными последствиями как для банка, так и для его клиентов. Поэтому именно в банках и компаниях fintech-сферы принято оперировать минимальными значениями RTO и RPO, так как в случае сбоя затраты на восстановление IT-инфраструктуры будут меньше, чем потенциальный ущерб от простоя.
Disaster Recovery в сфере обслуживания
Здесь ситуация с остановкой IT-сервисов и недоступностью данных может быть не такой критичной, как в банке, однако на практике все зависит от размеров бизнеса. Для службы доставки грузов с сотнями отделений по всей стране выгоднее оплатить сервис Disaster Recovery и застраховать себя от форс-мажорных ситуаций, когда убытки будут в несколько раз превышать затраты на данную услугу. Но для службы доставки продуктов питания в городе-стотысячнике остаться без подключения к основному серверу на несколько часов будет менее критичным событием, хотя и повлечет за собой как материальные убытки, так и репутационные потери.
Мнение эксперта Colobridge:
«Мы можем говорить лишь об условных отличиях использования Disaster Recovery в сфере обслуживания — на практике действительно многое зависит от скорости выполнения бизнес-операций. Даже среди компаний, которые предоставляют услуги экспресс-доставки грузов, ситуация может ощутимо разниться. Так, одни компании серьезно не пострадают после простоя длительностью в несколько часов, для других при тех же самых обстоятельствах убытки будут выражаться в шестизначных цифрах, так как склады мгновенно переполнятся, нарушится логистика, будут простаивать тысячи сотрудников».
Чем отличаются бэкапы от Disaster Recovery?
Сервисы создания бэкапов (например, BaaS — Backup as a Service) предполагают использование облачного репозитория только для хранения архивных копий, в то время как с DRaaS клиент получает сервис зеркалирования в облаке провайдера IT-инфраструктуры и возможность запускать виртуальные серверы в автоматическом режиме, если возникнет аварийная ситуация.
У DRaaS есть значительное преимущество перед BaaS: он позволяет быстро включить необходимую точку, чтобы как крупная, так и небольшая компания как можно быстрее и желательно незаметно для клиентов вернулись к нормальному режиму работы. Это становится возможным потому, что данные размещаются на продуктивном хранилище вместо того, чтобы храниться в заархивированном виде, как в случае с BaaS. Кроме того, облачный провайдер Disaster Recovery as Service предлагает больше настроек, возможность гибко управлять частотой создания (по расписанию) и параметрами восстановления виртуальных машин из резервных копий.
Репликация IT-инфраструктуры в облако с помощью DRaaS вовсе не означает отказ от традиционных бэкапов. Клиенты могут пользоваться этими двумя инструментами одновременно: «горячие данные» копировать раз в несколько часов и хранить в течение двух-трех дней, а копии «негорячих систем» делать ежедневно и хранить их, например, неделю. Настройку инфраструктуры в концепции Disaster Recovery компания делает подходящей под свои требования.
Технические решения Disaster Recovery от Colobridge
Услуга DRaaS, доступная на технологической платформе Colobridge, позволяет быстро восстановить виртуальные серверы в собственный облачный репозиторий, который фактически развернут в двух сертифицированных немецких дата-центрах уровня Tier III/Tier III+. Вы можете самостоятельно выбрать количество точек восстановления и частоту их создания или воспользоваться помощью наших экспертов. Они дадут развернутую консультацию с учетом специфики бизнес-нагрузок и бюджета на реализацию стратегии Disaster Recovery. В рамках услуги DRaaS можно арендовать любое количество виртуальных машин и любой объем вычислительных ресурсов, а впоследствии масштабировать решение по мере роста бизнеса.
Чтобы узнать больше о DRaaS на платформе Colobridge, получить рекомендации по опциям частоты создания копий и глубины архива, а также помощь в составлении плана аварийного восстановления данных (плана бэкапов), а также выработать алгоритм действий, обращайтесь к специалистам нашей компании — мы предоставим всю необходимую информацию, а по итогам протестируем и верифицируем Disaster Recovery Plan в соответствии с требованиями бизнеса.